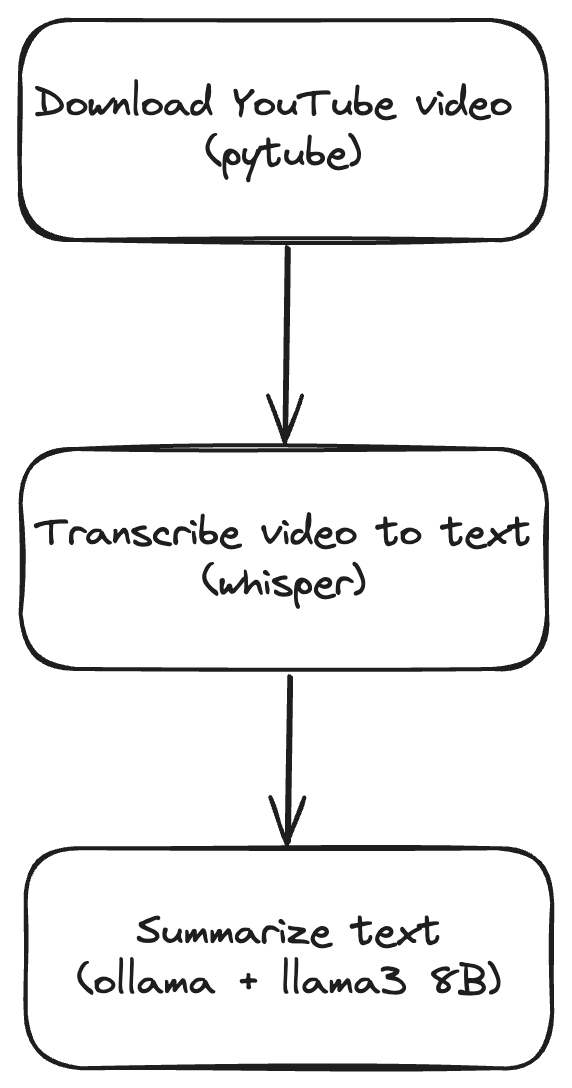
What I learned from the Mastering LLMs course

I recently signed up and completed the Mastering LLMs course on Maven and this post is to share what I learned from the course.
 (My certificate can be viewed online at https://maven.com/certificate/BBBPHevx)
(My certificate can be viewed online at https://maven.com/certificate/BBBPHevx)
This course was initially focused on LLM fine-tuning, but as more instructors joined, it somehow evolved into an LLM conference. Being based in Singapore, I usually could only watch the recordings later as the live sessions were often at inconvenient hours. That said, the advantage of watching the recordings is I could speed up playback by 1.5 to 2 times (depending on the speakers), pause when needed, rewind, and rewatch parts for better understanding.
Do not finetune until you prove that Prompt Engineering and RAG don't work for you
A common approach I was already familiar with is to start with Prompt Engineering, followed by Retrieval Augmented Generation (RAG), and then only consider fine-tuning. The reason is obvious -- fine-tuning is more costly, more work and has a slower feedback loop than the other two approaches. I already knew about this prior to the course but what I learned from the course is the added benefit of using Prompt Engineering and RAG results as baselines for fine-tuning.
Finetuning may yield worse results
Beware, fine-tuning isn’t always a guaranteed improvement! For instance, during one of the sessions, an example was shared where a model was finetuned on Slack chat data actually performed worse because the model kept trying to emulate the messaging style of the Slack users rather than actually answer questions based on the past chat conversations. (I was trying to recall the specific example but I couldn't find it after the course).
Axolotl + Cloud infrasturcture make finetuning very approachable
The course participants received in total $3,500 worth of compute credits for various providers (JarvisLabs, Modal, OpenAI, HuggingFace, Weights and Biases, etc.)
Thanks to the compute credits, I had the chance to experiment with fine-tuning a model using Axolotl on JarvisLabs and Modal. Modal is great for running code remotely with minimal setup. However, for fine-tuning, I preferred JarvisLabs as it offered me the control I needed without unnecessary complexities. I really don't need the bells and whitles that Modal provides.
Evals
This is interesting as the instructors have different opinions.
One basic method involves writing pytest unit tests to assert expected behaviors. This is unconventional for a software engineer like myself because unit tests usually avoid external calls, but here they recommend running such tests in production to act as guardrails.
There were also insights on using LLMs for evaluations, showcasing different perspectives on best practices.
A great insight I learned from one of the instructors is always try to turn what you're trying to evaluate into a binary classification. This makes it a lot easier to implement, reason about and evaluate in isolation.
Just use APIs (or No GPU before PMF)
While it’s intellectually stimulating to learn about setting up infrastructure for training and inference, many instructors emphasized the practicality of using cloud providers like Replicate and OpenAI for customer projects. Using APIs is great for prototyping and trying things out. Setting up your own infrastructure makes sense only if you have strict data privacy and security requirements.
Conclusion
This course was incredibly insightful and practical, providing a broad range of perspectives and hands-on experiences in the world of LLMs. The private Discord channel is a goldmine. Though the course lacks more structured and guided homework assignments that we can use to practice and assess our learning.
 (source:
(source: